One of the most technically interesting features I've built for Volitude was full-story text-to-speech narration.
Volitude generates personalised short stories for language learners based on their interests, reading level, and target language. Early versions of the app supported text-to-speech for individual words, but adding narration for entire stories introduced a surprisingly difficult set of engineering problems.
I wanted the experience to feel seamless:
- User presses “Listen”
- Narration starts quickly
- The currently spoken paragraph is highlighted in-sync
- Playback continues smoothly across the whole story
Getting all of that to work together took several iterations.
The Initial Problem
At first glance, story narration seems straightforward:
- Send story text to a TTS provider
- Receive an MP3 file
- Play it in the browser
The real challenge appears once you try to synchronise narration with the UI - how does the React component know which paragraph is currently being read?
I wanted the currently spoken paragraph to highlight while audio played to make it easier for the reader to follow along. Browser-native speech synthesis APIs didn't provide enough control or consistency across devices, particularly around timing metadata and playback behaviour. They also sound extremely robotic.
I eventually chose Google Cloud Text-to-Speech because it supports SSML marks and timepoints. That meant I could inject markers into the generated speech and receive precise timestamps back from the API.
Generating Synchronised Speech with SSML
Google Cloud TTS supports
SSML
<mark> tags, which return timestamps during synthesis.
Each paragraph receives a marker before synthesis:
<speak>
<mark name="title"/>
<p>Story title</p>
<mark name="p0"/>
<p>First paragraph...</p>
<mark name="p1"/>
<p>Second paragraph...</p>
</speak>
The synthesis response then contains timepoints like:
[
{ "mark": "title", "timeSeconds": 0.0 },
{ "mark": "p0", "timeSeconds": 1.2 },
{ "mark": "p1", "timeSeconds": 8.6 }
]
These timestamps allowed the frontend to determine which paragraph should currently be highlighted.
Synchronising Playback with React
On the client side, playback used a native HTMLAudioElement. The player listens for timeupdate
events and maps the current playback time to the most recent paragraph marker.
function computeActiveParagraphIdx(currentTime: number): number | null {
const tps = timepointsRef.current
.filter((tp) => /^p\d+$/.test(tp.mark))
.slice();
tps.sort((a, b) => a.timeSeconds - b.timeSeconds);
let idx: number | null = null;
for (const tp of tps) {
if (tp.timeSeconds <= currentTime) {
idx = Number(tp.mark.slice(1));
} else {
break;
}
}
return idx;
}
The active paragraph was then highlighted with simple CSS state changes.
This sounds simple in isolation, but coordinating playback state, async synthesis, transitions between segments, and React rendering behaviour quickly became rather tricky.
The Latency Problem
Generating narration for an entire story could take up to 25 seconds. No user is going to wait that long for the audio to load - that was unacceptable UX.
My first solution was aggressive optimisation:
- Generate the title and each paragraph in separate requests
- Stream playback paragraph-by-paragraph
- Prefetch future paragraphs while the current one played
In theory, this reduced time-to-first-audio dramatically. In practice, however, it created a huge amount of operational complexity.
The Paragraph-by-Paragraph Architecture
Request 1: Title /api/tts/synthesize?segment=title
Request 2: Paragraph 1 /api/tts/synthesize?segment=p0
Request 3: Paragraph 2 /api/tts/synthesize?segment=p1
Request 4: Paragraph 3 /api/tts/synthesize?segment=p2
...
The original architecture required:
- Managing queues of audio clips
- Orchestrating transitions between several playback events
- Handling partial failures
- Retrying missing segments
- Dealing with browser timing inconsistencies
- Synchronising highlights across multiple audio files
The edge cases multiplied quickly:
- A paragraph finishes before the next is ready
- Playback stalls mid-story
- Duplicate synthesis requests occur
- Audio desynchronises from highlighting
- Pause/resume behaviour becomes inconsistent
- React re-renders interrupt playback state
The system became fragile and difficult to reason about. It was fixable, but not in a reasonable amount of time for a PoC feature.
The Two-Segment Redesign
Eventually I stepped back and reconsidered the problem.
Did I actually need fully granular streaming? The answer was no.
Instead, I redesigned the system around two segments:
Segment A: Title and first paragraph
Segment B: Remaining paragraphs
This dramatically simplified the orchestration model. The first segment could be generated quickly enough to feel responsive, while the second segment generated in parallel in the background.
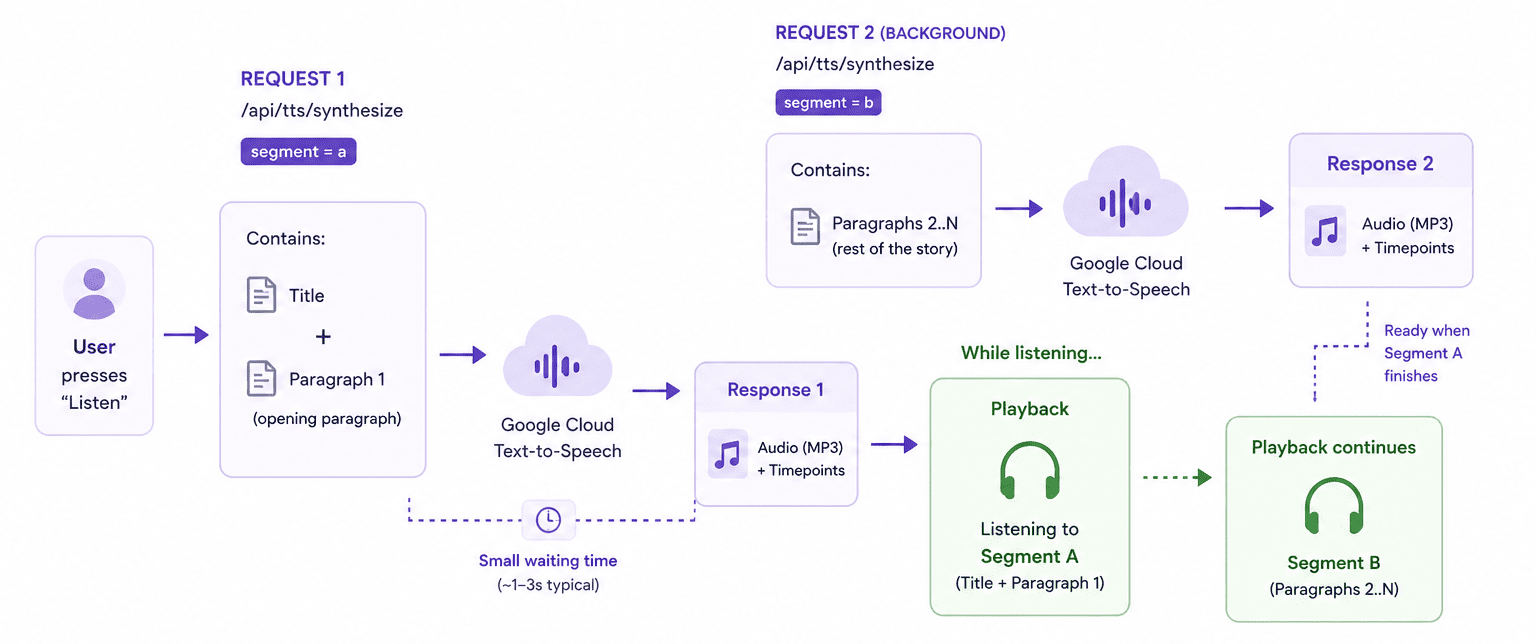
Crucially, including the first paragraph in Segment A avoided a subtle UX issue. If Segment A only contained the title, playback could reach the end of the title before the next segment finished synthesising, causing an awkward pause. Adding the first paragraph provided enough buffer time for Segment B to finish reliably.
Fighting React Re-Renders
One of the most frustrating bugs came from React lifecycle behaviour. Playback would occasionally stop unexpectedly because effect cleanups fired during re-renders.
The fixes required careful separation between:
- Reactive UI state
- Mutable playback state
- Long-lived async operations
That's why the final implementation relies heavily on refs:
const audioRef = useRef<HTMLAudioElement | null>(null);
const timepointsRef = useRef<Timepoint[]>([]);
const nextSegmentPromiseRef = useRef<Promise<SynthesizeResponse> | null>(null);
Refs allowed playback state to persist independently of React render cycles. The player lifecycle eventually became much more stable once I stopped trying to make everything reactive.
Preventing Duplicate Synthesis Requests
Another problem surfaced under concurrent rendering and repeated client requests - without protection, the same story could trigger multiple simultaneous synthesis jobs.
The backend solved this with in-flight request deduplication.
const inFlight = new Map<string, Promise<Result>>();
const existing = inFlight.get(key);
const job = existing ?? synthesize();
if (!existing) {
inFlight.set(key, job);
job.finally(() => inFlight.delete(key));
}
This ensured only one synthesis job ran per unique story segment.
Caching Audio
Synthesising speech repeatedly would have been both slow and expensive.
Each segment therefore receives a deterministic content hash based on:
- Language
- Speaking rate
- Segment type
- Title
- Paragraph content
Generated MP3s and metadata were then cached in Redis.
await redis.set(metaKey, meta);
await redis.set(audioKey, audioMp3.toString('base64'));
Redis wasn't the ideal long-term storage layer for binary audio blobs, but it already existed in the stack and dramatically simplified the first implementation. That tradeoff was worthwhile to get the feature into users hands sooner.
Architecture Overview
The final architecture looked something like this.
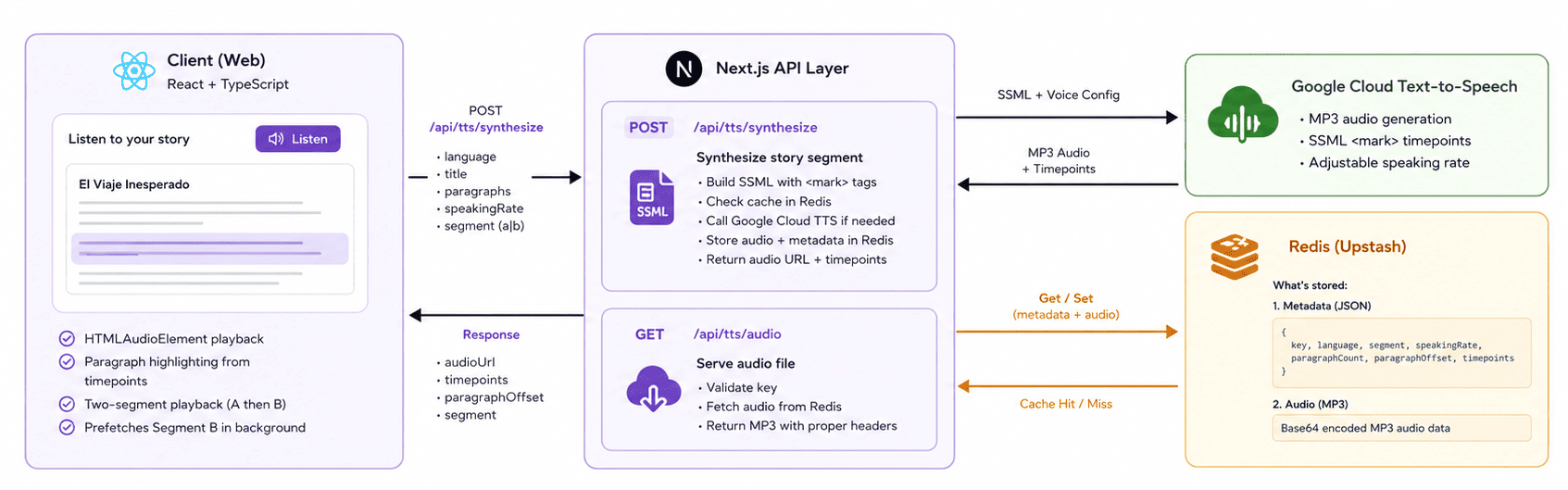
Lessons Learned
The biggest lesson from this project was that simpler systems are often better systems.
My original design aggressively optimised for latency, but introduced too much orchestration complexity:
- Too many transitions
- Too many failure states
- Too many async interactions
The two-segment architecture achieved most of the performance gains while remaining understandable and reliable. That tradeoff mattered far more than theoretical optimality.
Future Enhancements
There's still a lot I'd like to improve.
Playback Controls
The current player is intentionally minimal. Future improvements could include:
- Rewind/skip controls
- Playback speed adjustment
- Scrubbing through audio
Line-by-Line Highlighting
Paragraph highlighting works well, but sentence-level or line-level highlighting would create a more immersive reading experience.
That would likely require:
- Additional SSML marks
- Denser timing metadata
- More sophisticated synchronisation logic
Object Storage
Redis works well for prototyping, but audio blobs are better suited to object storage.
A future version would likely:
- Store MP3s in blob/object storage
- Keep only metadata and lookup keys in Redis
- Serve audio through a CDN
Observability
The current system has very little operational visibility.
I'd like to add:
- Synthesis latency metrics
- Cache hit rates
- Playback failure tracking
- Segment transition timing
- Provider error monitoring
Final Thoughts
This feature ended up being much more about systems design than text-to-speech itself.
The difficult part wasn’t generating audio. It was coordinating:
- Asynchronous synthesis
- Frontend playback
- UI synchronisation
- Caching
- Browser behaviour
- React rendering
- Network reliability
The final implementation is dramatically simpler than the original one I envisioned. And that's probably why it works!
If you'd like to see this feature in action, you can onboard for free today and head to the Daily Story.